




Helloo! Another attempt at a detailed blog post on designing a web crawler, covering all key aspects structurally:
Designing a Scalable Web Crawler
A web crawler is a program that browses the web to index pages systematically. Web crawler is generally built for
Search Engine
2. Web malware detection .
Web Analytics (to read in depth about analytics data collection for E-Commerce click).
Complete design of web crawler can be split into two 1.GATHERER 2. EXTRACTOR
GATHERER:
collect/download all the data from the web page (a given web page). ie say a category page of Amazon or a detail page of Amazon, as the category page of india region follows the same template this gather can collect all the different categories and from the category, it will get link to the product url and detail page(single product page template) like this when a SEED URL is given the crawler is able to download /gather/collect all the needed data that we need for further analytics, SEO, URLs.
EXTRACTOR :
Extract the data we need from the downloaded data gathered (including image, video, and URLs which is processed later) in this way we can modify the data collected data(from gathered) for analytics/SEO and other use cases.
Functional Goals
Crawl trillions of web pages
Handle politeness constraints
Store pages optimally for indexing (gathering/collection of data from Internet[www]) & extract links to guide further crawling (extraction)
Avoid Duplicate crawling
Prioritize crawl frequency based on change rates
Ensure crawl rate limits per domain
Non-Functional Goals
Highly scalable
Consistent hashing for load distribution
Extensible to handle newer protocols
Easy addition of new page processor modules
Back-of-the-Envelope Estimation
Capacity Estimations
Pages to Crawl
Total websites: 900 million
Assumed functional sites: 60% = 500 million
Average pages per site: 100
Total pages to crawl: 500 million * 100 = 50 billion
Page Size
Avg index page size:
Total page size: 200 KB
Remove images, media: 100 KB
Metadata per page: 500 bytes
Storage Estimates
Raw page content
50 billion pages
100 KB per page
Total storage: 50B * 100KB = 5000 TB = 5 petabytes
Metadata for 50B pages
500 bytes per page
Total metadata storage: 50B * 0.5KB ~ 25 TB
Checksum index for deduplication
8 bytes per page
Total storage: 50B * 8 bytes = 400 GB
Unique URLs seen checksum index
2 bytes per URL
Total storage: 50B * 2 bytes = 100 GB
Bandwidth Estimates
50B * 100KB per page = 5000 TB total
Crawling entire web monthly: 5000TB / 30 days = 165 TB per day
So in summary, we need to provision for:
5 petabytes of raw storage
165 TB inbound bandwidth daily
Sufficient compute for 50 billion page crawls monthly
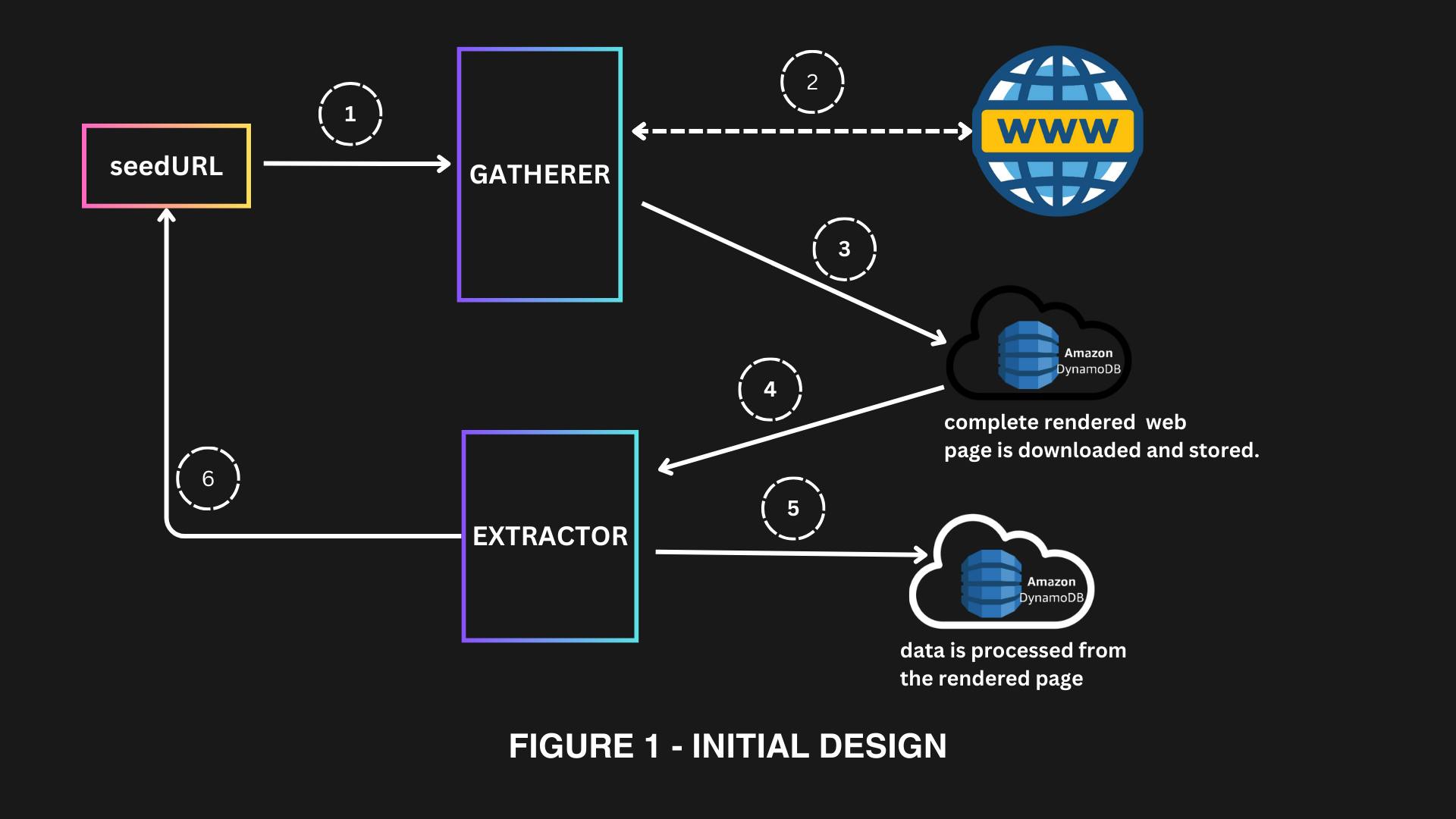
Figure 1 - Initial design
High-Level Architecture
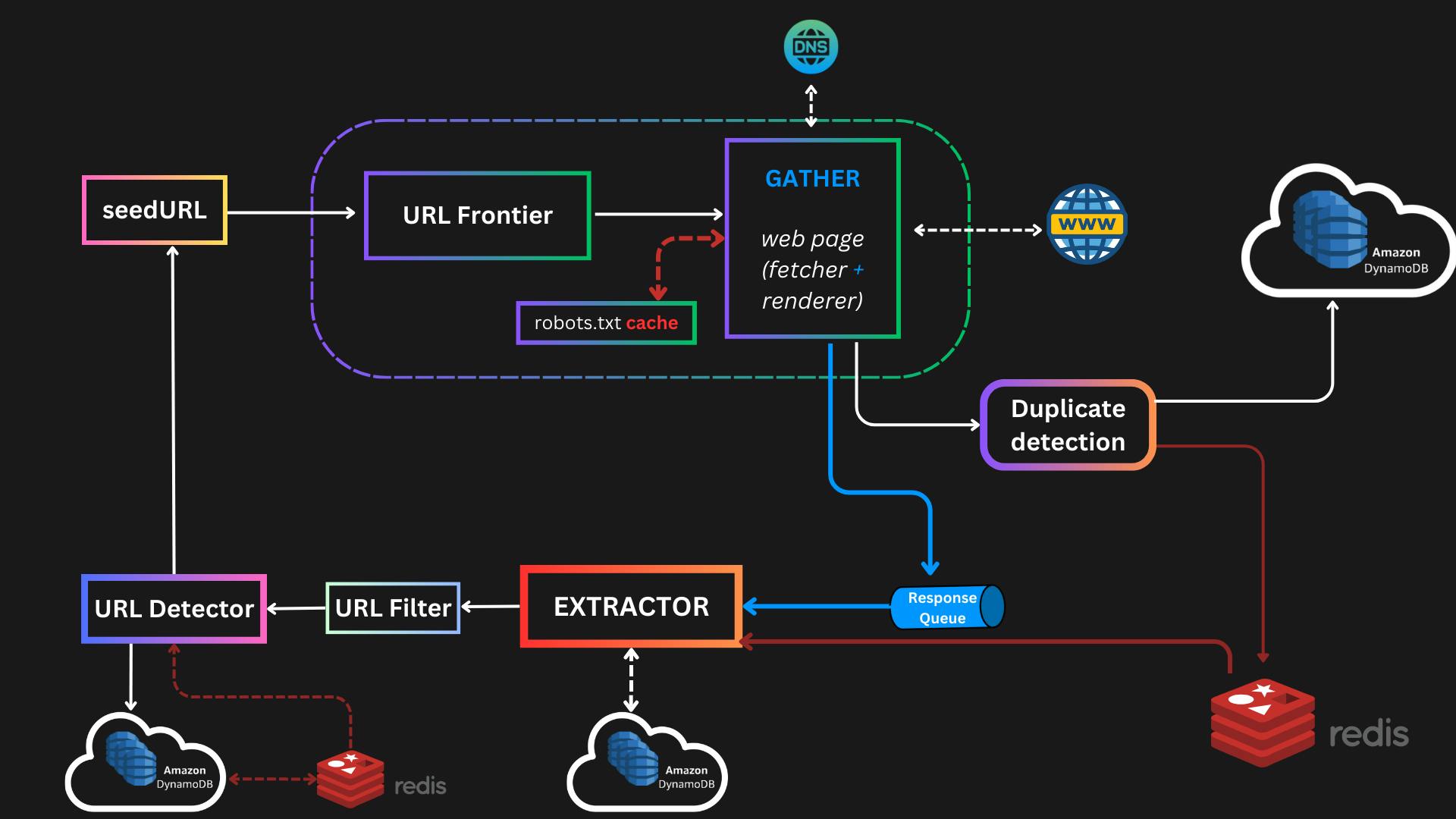
The web crawler runs on a distributed cluster with the following key components:
we have many workers/jobs/ threads waiting to gather the url, this leads to 3 problems
Seed URL - This can be given by the user and also cycled by the crawler.
URL Frontier - Manages URLs to crawl using queues hosted across worker machines.
DNS Resolver - Maps hostnames to IPs with caching for performance.
Note: When end user humans enter a url the DNS is heavily cached across the "browser", system, router, and DNS resolver. But here the case is different there is no human intervention and so when the URL is called the call has to be made across the network which degrades the performance soo we introduce a dedicated DNS server to improve the performance and this is mandatory because the calls are made at the network level. "The Low-level implementation and extensibility of this specific feature is discussed in detail here"
GATHER - Downloads page content from servers respecting politeness constraints.
NOSQL DB - better for storing large sets of heterogeneous data (html, JSON,mp3, image, video and more).
NOSQL DB - For storing the metadata of the websites.
Redis - To store the same data as read and write operations are much faster, implementing Redis here we can design 1st write to Redis and then let a cron job/ worker can write the data from queue to NOSQL DB.
This design significantly improves the performance as the Extractor service will get the data from the Redis cache not from NOSQL DB. this enables us to compress the data and write to DB saves storage, since the url and all data required are present in the cache its consumed by Extractor service for further processing.
Response Queue - will have the URL and its response is 200 proceed, else retry the URL for 3 attempts (depending on interviewer requirement).
Extractor - To extract the data from the downloaded web pages. Data not limited to price, customer reviews, brand, and offers for analytics from an e-commerce pov and also extract HTML links that is fed back as seed URLs to crawl further.
Duplicate Detection - Around 30% of web pages contain duplicate content, which can lead to inefficiencies and slowdowns in the storage system if the same content is stored multiple times. To identify and prevent the storage of duplicate content some algorithm use Hashing (MD5), minwise Hash, simhash (google uses simhash), and fuzzy search.
URL Filter - when we are crawling for web scraping to limit some malicious urls are identified and filtered out so that are are not used as seedUrl, Say we are crawling stockExchange analytics we may need only images but not .mp4 or other video formats. Filtering out and use only the necessary URL can be done by simple regex.
URL Detector: Used to filter out URLs that have already been visited. This helps to prevent the system from getting stuck in an infinite loop where the same URL is processed repeatedly. This component must at the final component ie must be the component after extracting the URLs that are extracted to be crawled for data.Some techniques to implement the URL Detector, such as Bloom Filters and Hash Tables. These techniques efficiently identify already visited URLs, so that they can be skipped in the crawling process.
Robot.txt Cache: This cache is required when fetching the website the web master defines the rules for what data is to be crawled and not in this file, instead checking each time the page contents are legal to scrape or not fom the robot.txt file from the server (eg amazon server) we can save that is a cache, saves overhead.
Component Design
Now let's explore each component's functionality and scalability challenges:
URL Frontier
Requirement:
Should hold and send every URL to crawl/scrape to "GATHER" in right order: For this BFS is preferred over DFS because by BFS we move through level by level. Meaning if we are in the category of kids in myntra (https://www.myntra.com/kids) By BFS we will crawl through/get all the product URL / data of each product and then open/render the product one by one. On the other hand in DFS in goes to the depth of one link and then comes back and repeats, in some cases crawler may get into traps and may gather unnecessary data.
URL Frontier must know when to crawl for already crawled site say news are updated more frequently than company's home page and company's blog page for this URL Frontier should maintain some sort of priority so that all sites are eventually crawled.
Another important thing to consider is POLITENESS: ie. if the gather has 100 free threads, means I cannot make 100 calls to a same server in a second because that violates Robot.txt and the server response will become slower If the server implements Cloudflare and other antibot detection mechanism crawling from the same IP will become harder (as the credibility if IP will degenerate) the to get the data we have to follow anti-bot crawling strategies.
Datastructure to store all urls
Priority - what web page should be crawled again when ?
Poiliteness
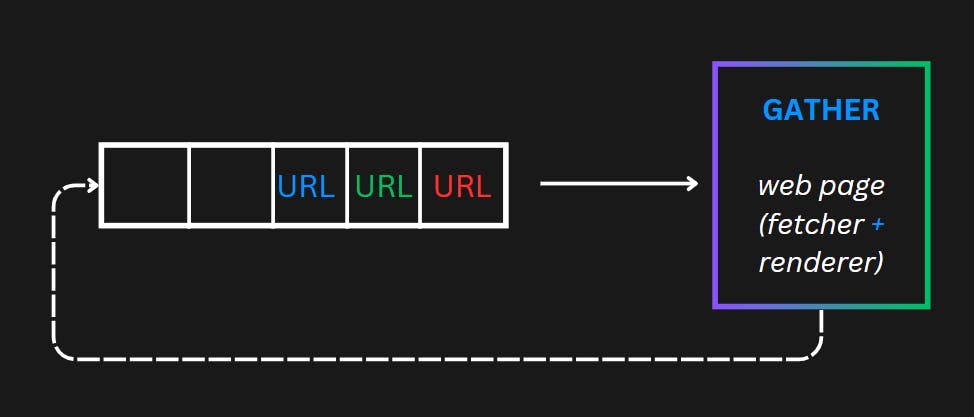
This is a simple queue that can take all incoming crawler and give it to gather for data extraction, but this design leads 2 problems politeness and Priority of Urls are unassigned.
We can have a service that can assign priority to the URLs and assign URLs to queues based on priority. By this way we now know what URL should be crawled first, the assigning priority is based on a set of paramaters like the nature of content eg. news, stock data(high priority) or Travel blogs(low priority).
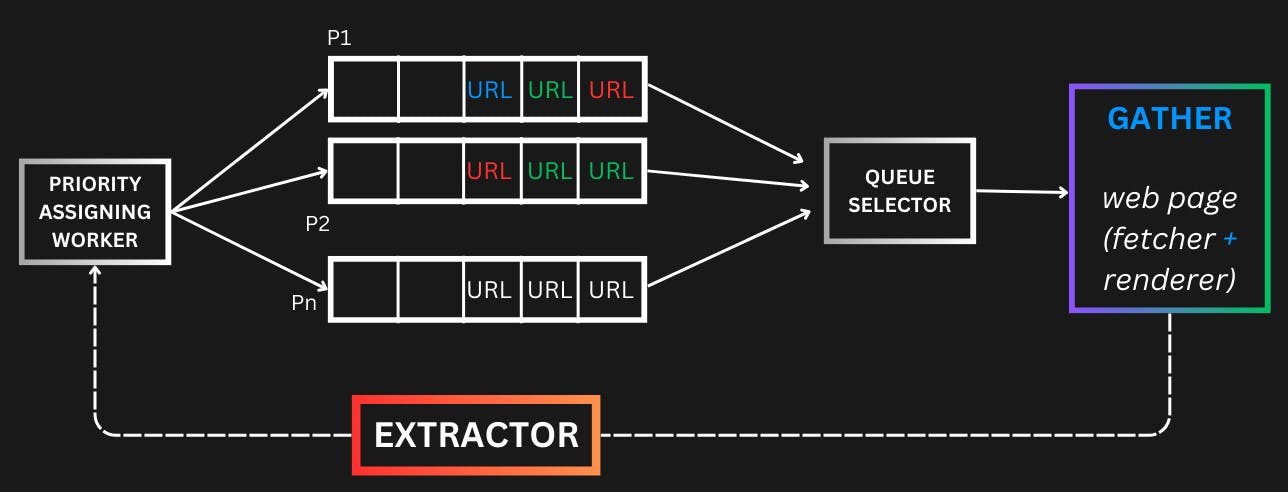
By this approach, the high-priority queue(URLs) are called more frequently and remaining all URLs are called eventually and data extracted.
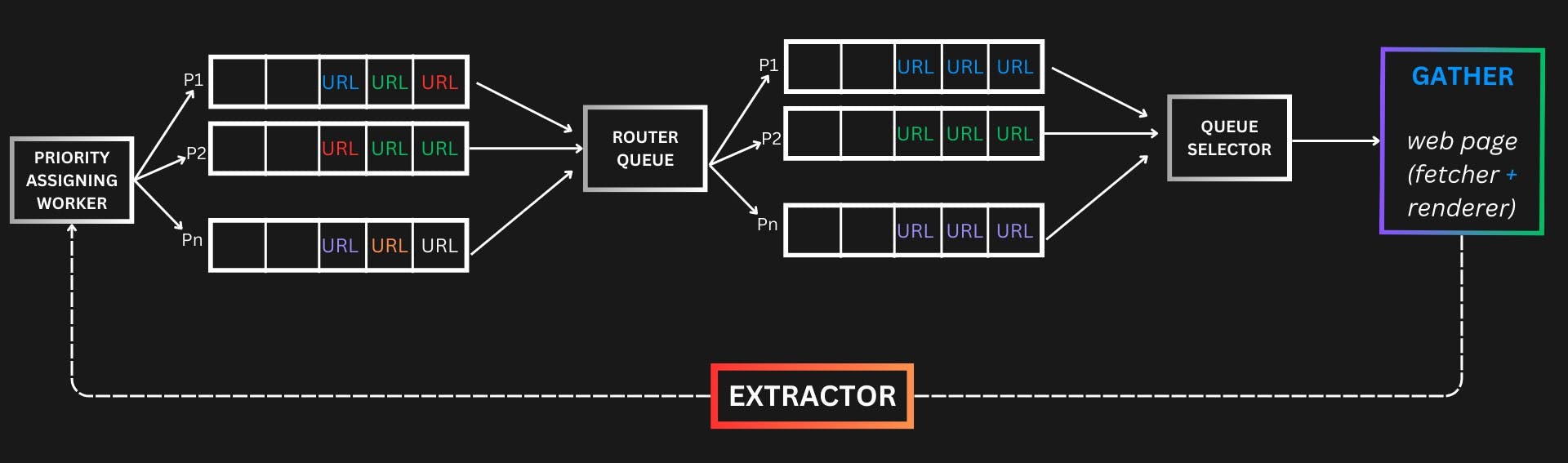
Now we separated the complete URLs and know what URL to crawl when but the problem of politeness remains ie. Let's assume a case where the stock URL is in the Highest priority and all URLs are Stock URLs but the robot.txt file and server does not allow multiple concurrent calls made from the same IP (also many other parameters refer to Mastery of web Scraping) so we need to find a way to delay the calls made. One approach is to have a delay between each calls. But in our current design we have in a queue multiple domain URLs. To keep track of time to call between each url request in a distributed system is trying. so we can implement.
Have a dedicated queue for each domain and a Heap for each queue. In this way, we can introduce the necessary delay we need to make between each call. Min Heap will contain the queue ID and the time, so always the minimum URL will be crawled.
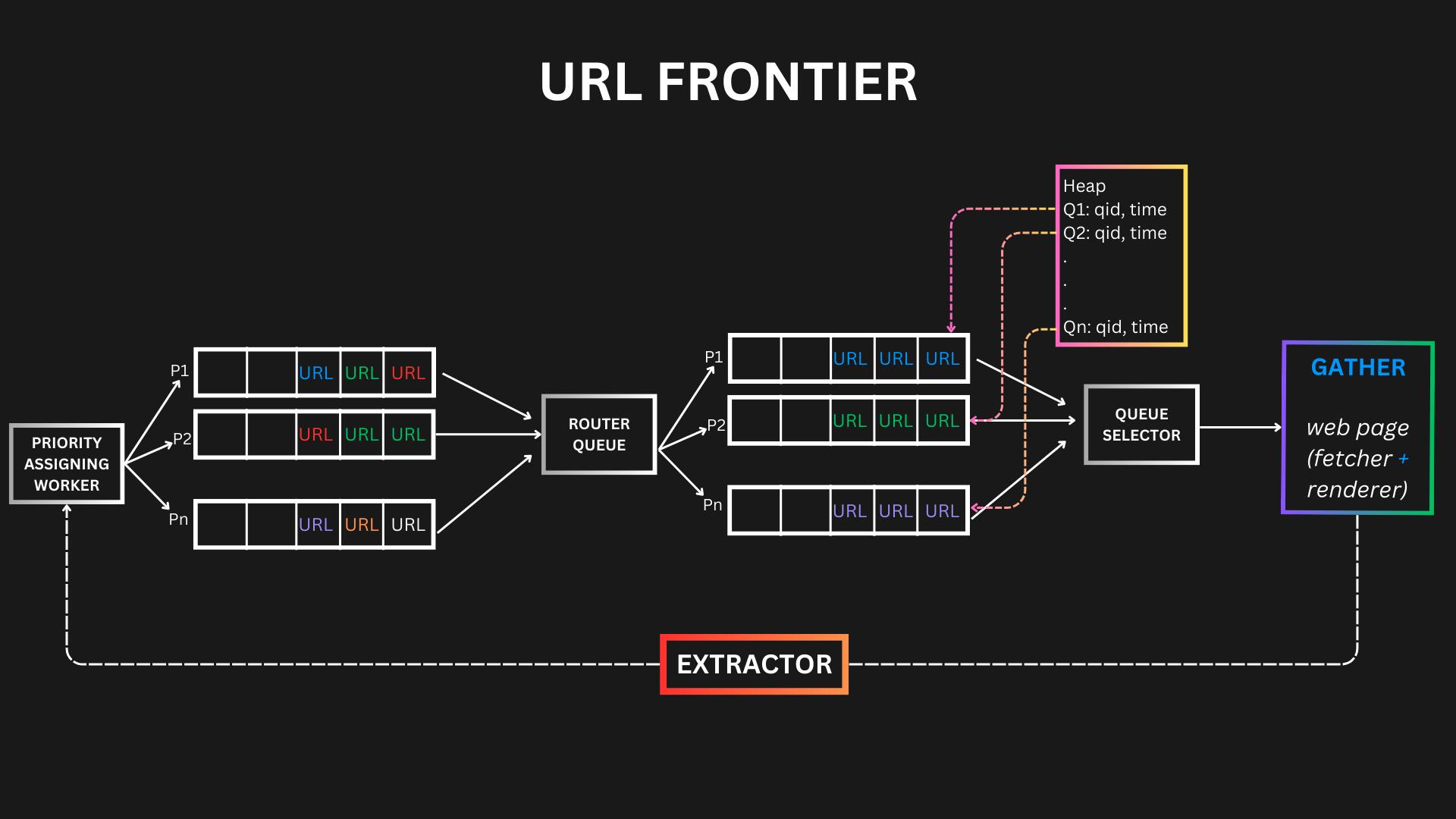
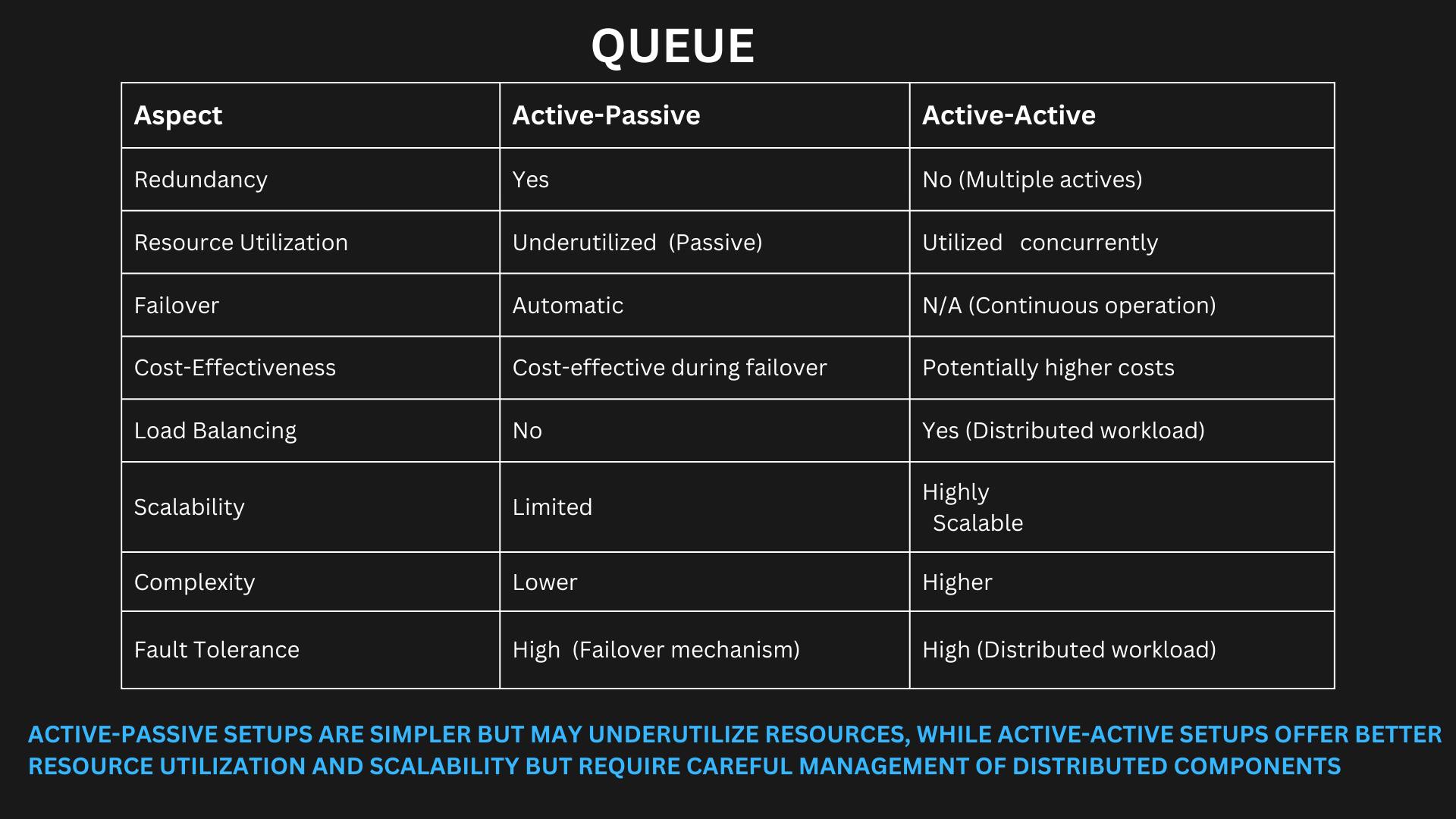
Active- passive queue mechanism can be implemented for high avaliability.
Extractor
This itself is a huge component for now let's keep this simple. When the extractor gets response 200 from the response queue for a given URL instantaneously that data is fetched from the Redis cache and parsing the data for bussiness requirements for E-Commerce. I would collect as much analytical data which is not limited to price, offers, customer review and average rating of every product their seller to find the competitor prices and store this in a relational database as complex queries exist and dashboards are used for analytics and latency are allowed here.
THIS COMPONENT WILL BE EXPLAINED IN DETAIL LATER for quick overview click
URL Detector
This component will check whether the given url is already checked or not, it uses the Bloom filter to do it. URL Detecotr has a dedicated Database containing all the URLs come so far. selection of this Database can be a NOSQL read is faster and no complex queries is required Redis cache we can also have HDFS or other. Must be read fast.
Cache
Gather will write directly to cache and compress and store data in DB, LRU can be used for cache eviction in this stage.
Extractor extracts the data from the Redis cache itself.
Extractor saves the parsed data for analytics/search engine in NOSQL database as it can scale and read ratio higher (mostly when connected to other systems for analytics). If the queries are more complex we can introduce SQL DB.
URL Detector will check if the collected set of URLs has any duplicate values this need not give 100% accurate value some misses are allowed to get away. To store all set of URL we use NOSQL (read operations a re much faster and have no joins)
Read Through cache stager can be implemented in URL Detector level (whenever there is a read request, data is first checked in the cache. If a cache miss occurs, data is fetched from main memory and stored in the cache. Future reads will then hit the cache).
Bottlenecks
Deduplication Details
Elaborate on approaches like Simhashes
Tradeoffs vs other methods like minhash
Where checksums get stored, accessed from
Distributed Coordination
- Zookeeper to coordinate the components when failover occurs, smooth transition for the active-passive model. Or Azure Service Bus (scalability and fault tolerance made easy)
We used queues and heap to limit the number of hits to server, alternatively we can use rate limiter.
Scalability Considerations
Vertical Scaling
Scale up individual servers based on resource envelopes rather than contention.Horizontal Scaling Distribute load across commodity machines via consistent hashing.
Data Partitioning Shard databases and distributed queues by checksum ranges.
Caching In-memory LRU caches to avoid duplicate IO.
Operational Challenges
Crawler Traps - Escape loops by penalizing fast link repeats
Fault Tolerance - Handle worker failures via consistent hashing
Monitoring - Gather health metrics for alerts and debugging
Questions to ask yourself
How would you design a distributed web crawler to operate efficiently across multiple geographic regions?
What strategies would you employ to prevent web crawlers from getting blocked by websites? Discuss techniques like IP rotation and proxy management.
How do you ensure scalability and optimal performance for a web crawler, especially when dealing with a large number of URLs?
What metrics would you track to monitor the health of a web crawler? Discuss key performance indicators for effective monitoring.
How do you handle dynamic content loaded via JavaScript in a web crawler? Explain techniques for extracting data from dynamically generated pages.
Explain the importance of respecting
robots.txtin web crawling. How would you design a crawler to adhere to the rules specified in this file?Discuss the concept of politeness in web crawling. How would you implement rate limiting to avoid overloading servers and being blocked?
Describe strategies for debugging failures in a web crawler, especially when critical pages are missing. How do you maintain robustness in crawling?
What are the key differences between a focused web crawler and a general web crawler? How would you tailor the crawling strategy based on specific use cases?
When designing a web crawler, what considerations would you make regarding DNS resolution? Discuss the pros and cons of blocking vs. non-blocking resolution.
How do we prevent infinite URL redirection?
How do you determine that crawling has actually been completed?
How do we prevent infinite URL redirection?
HEAD request gets if the URL content has already changed or not if changes then do the crawling.
Here is one approach to prevent infinite URL redirections in a web crawler:
- Maintain a URL redirection history and track the number of hops:
- Every time a URL redirects to a new location, store the original and redirected URL in a request history table/log along with a timestamp
- Before processing a redirected URL, check if it exists in history:
Lookup the redirected URL in the request history
If it exists, increment a counter to track number of hops/redirects
- Drop processing if depth exceeds a threshold:
Define a max depth limit, e.g. 5 redirects
If number of hops for a URL exceeds depth limit, stop processing that URL
- Tag these URLs as blocked:
Maintain a separate table/cache of blocked URLs
Add any dropped URLs to this list
- Periodically retry blocked URLs:
- In case site fixes the redirect issue later, unblock
This allows stopping and blacklisting URLs going into endless redirects while keeping flexibility to retry a blocked URL later, in case it gets resolved downstream.
Let me know if you need any clarification or have additional questions!
References: Leetcode, Google Docs.